个性化推荐:用户的期望和假设
 Free-Photos
Free-Photos
摘要:用户喜欢个性化的内容建议,愿意放弃一些个人隐私以获得更好的推荐。
根据收集到的用户偏好和行为数据,网站和应用可以做到个性化推荐内容。
个性化推荐可以基于机器学习或其他人工智能技术,以及来自用户的明确定制或组合使用。
数据收集
目前主要使用以下信息来生成个性化推荐:
历史记录-过去的购买或消费的内容(例如购买的商品。观看的视频,在内容服务上播放的歌曲) 用户输入的个人资料数据,包括年龄,性别和位置等人口统计信息,以及兴趣类别或特定网站的上下文信息 等级 保存或“收藏”的物品 浏览行为 搜索历史记录
如何识别个性化内容?
用户主要依靠明确的标题(例如,推荐给你, 因为你观看了)。除了这些明显的指标之外,还可以使用间接线索(例如,所建议的项目整体受欢迎程度或特定的促销广告)来确定该项目是否为个性化推荐。
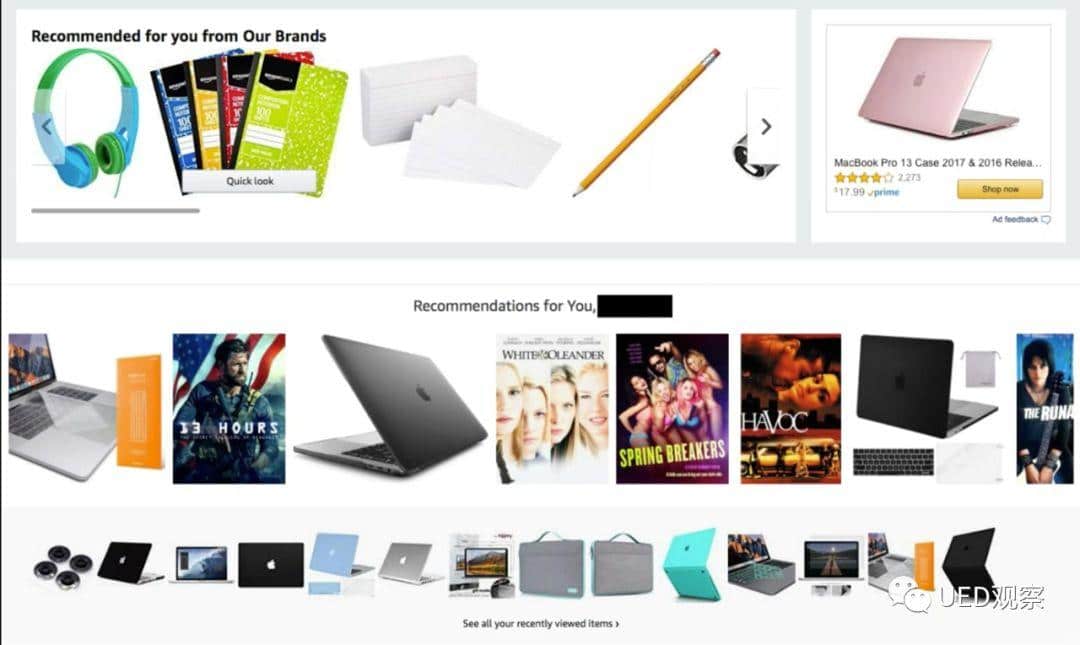 Amazon.com:含有“你”的标题是个性化内容的清晰标记。
Amazon.com:含有“你”的标题是个性化内容的清晰标记。
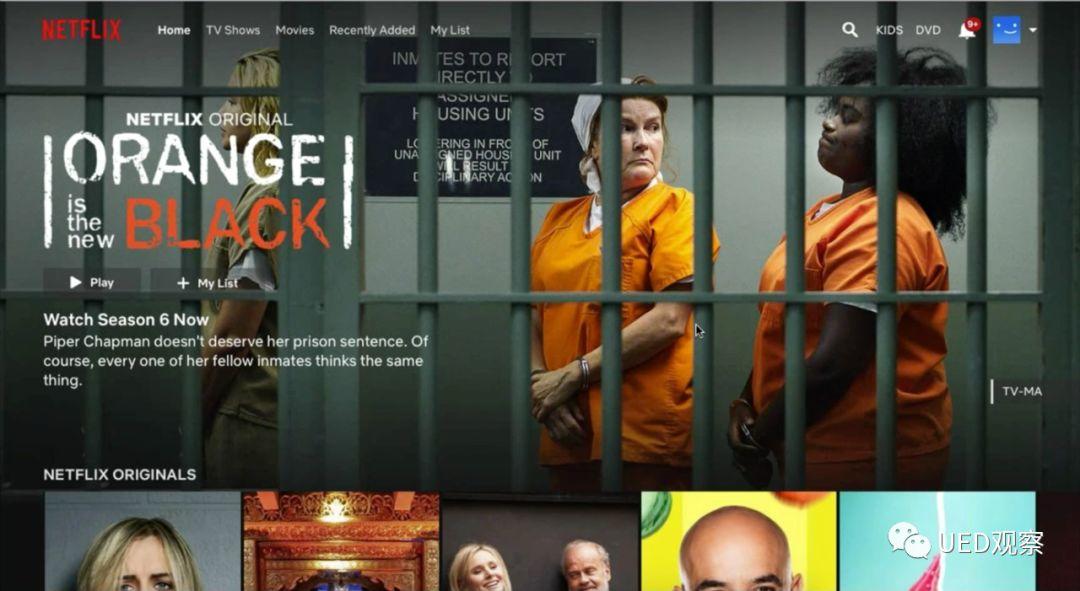
Netflix:用户认为最近发布的新剧有足够的商业理由向所有用户推荐,因此它是普通促销活动。
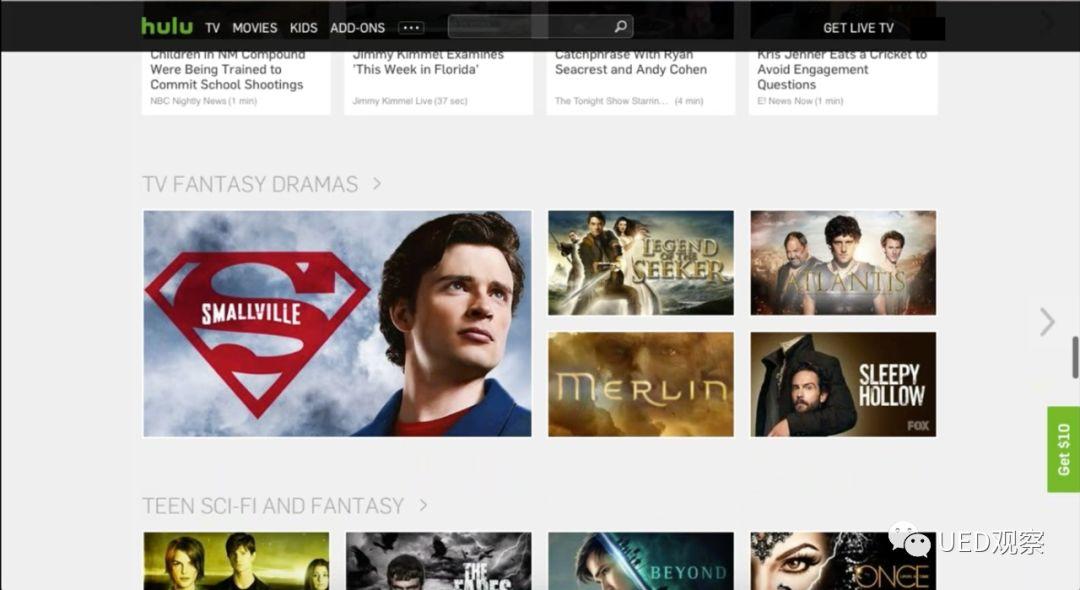
hulu.com用户认为会根据他的个人兴趣来显示网站上的电视剧,他觉得大多数人对此类节目不感兴趣。
技术限制
当多人共享一个帐户时,推荐系统通常很容易出错,因为系统需要容纳多个彼此竞争的数据源。
不好的建议会被忽略
用户并不介意错误的推荐,而是会继续浏览他们关心的内容。
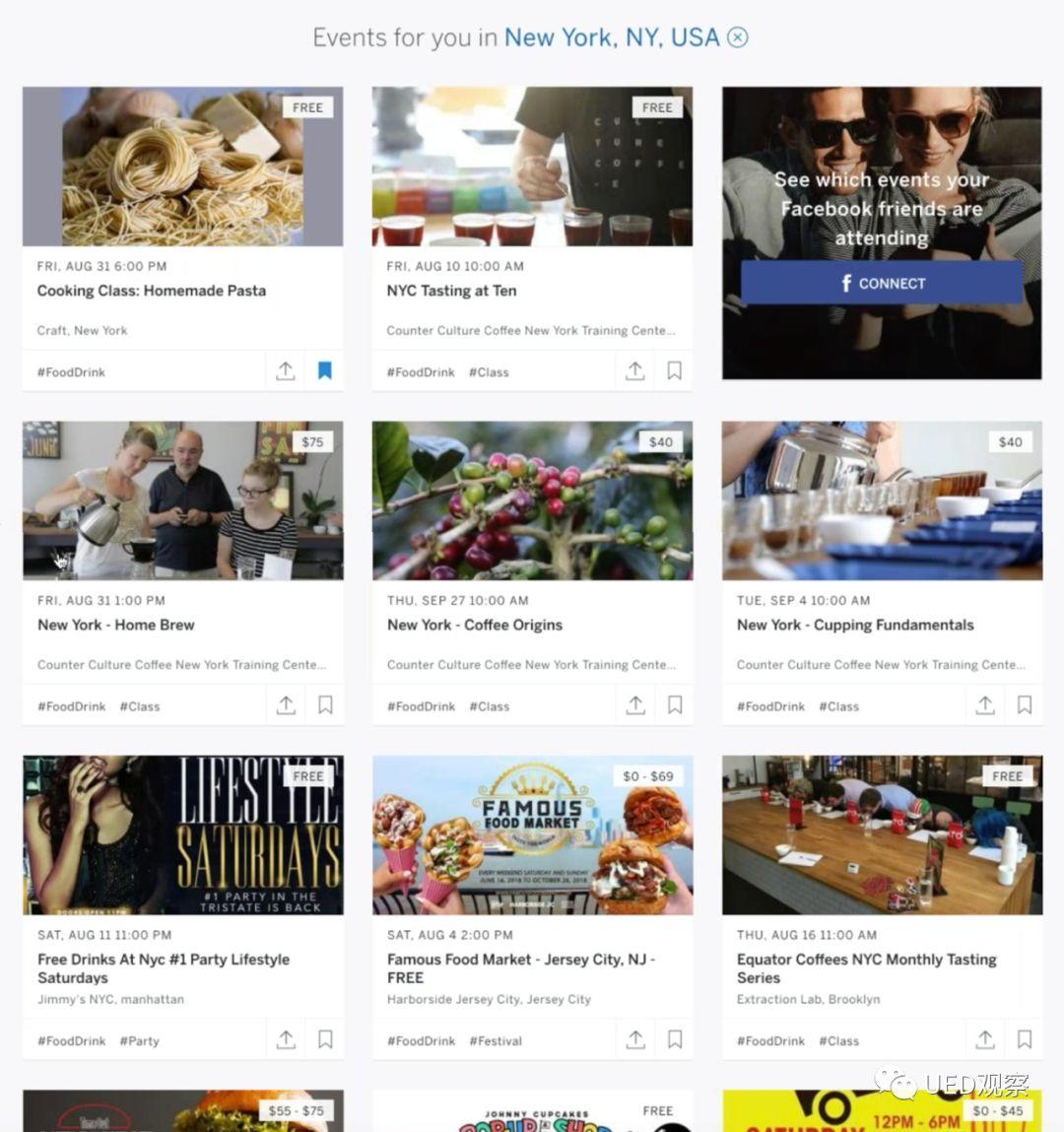 Eventbrite:用户认为不受欢迎的推荐容易被忽略。她不想花力气向网站介绍自己的喜好。
Eventbrite:用户认为不受欢迎的推荐容易被忽略。她不想花力气向网站介绍自己的喜好。
结论
跟踪网站和数字产品使用情况以呈现个性化内容并不被视为对用户的隐私侵犯。
相反,个性化(例如个性化推荐)被视为一种功能,这表明网站试图通过帮助用户缩小选择范围来更好地为用户服务。可怜的建议很容易被忽略,或者,当获得好建议的好处足够大时,用户甚至愿意进一步参与帮助改善系统推荐的准确性。


